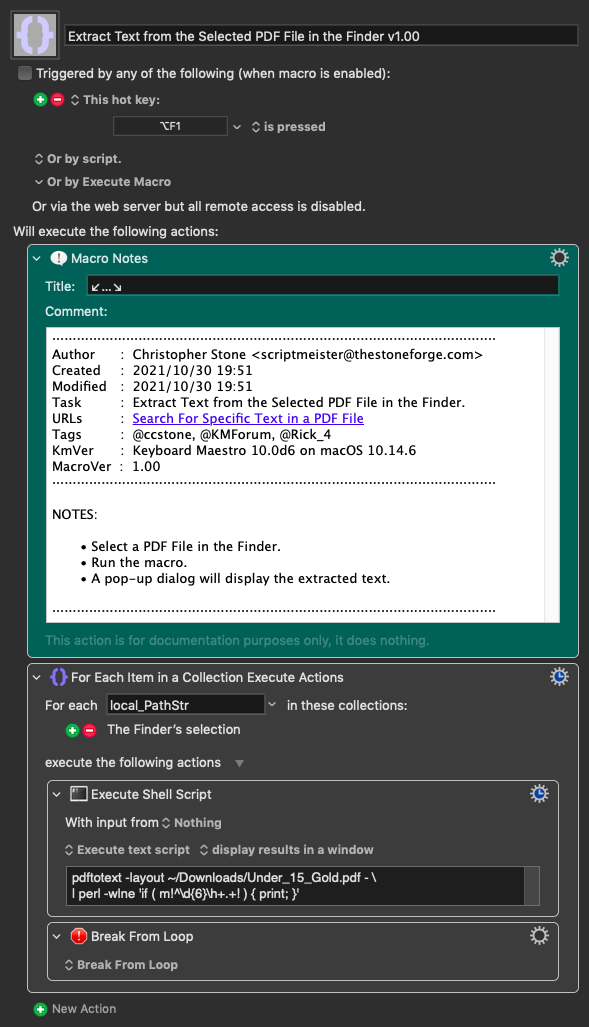
From this kind of document I need to create a .txt like this:
Name= name of the currrent document + _GironeVerde
First line empty
2021
GRANDA COLLEGE CUNEO
TAM TAM
B.C. GATORS
SCUOLA BASKET ASTI
A. SPORTIVA DIL. PALL. ABA SALUZZO
O.A.S.I. LAURA VICUNA
ASD BASKET CLUB SERRAVALLE
A.S.D. PALL. FARIGLIANO
USAC RIVAROLO BK 2009
PALL. GRUGLIASCO
PALLACANESTRO CIRIE'
ALFIERI
A.S.D. 5 PARI
A.S.D. OLEGGIO JUNIOR BASKET
FULGOR OMEGNA
ETEILA BASKET
Name= name of the currrent document + _GironeRosso
First line empty
2021
O.A.S.I. LAURA VICUNA
ASD BASKET CLUB SERRAVALLE
A.S.D. PALL. FARIGLIANO
USAC RIVAROLO BK 2009
PALL. GRUGLIASCO
PALLACANESTRO CIRIE'
ALFIERI
A.S.D. 5 PARI
A.S.D. OLEGGIO JUNIOR BASKET
FULGOR OMEGNA
ETEILA BASKET
This AppleScript will return the text content of a given PDF file whose path you supply:
use framework "PDFKit"
use scripting additions
property this : a reference to current application
property NSString : a reference to NSString of this
property NSURL : a reference to NSURL of this
property PDFDocument : a reference to PDFDocument of this
on pdfText from pdf_filepath as text
set pdf_pages to {}
tell PDFDocument's alloc()
initWithURL_(fileURLWithPath_((NSString's ¬
stringWithString:pdf_filepath)'s ¬
stringByStandardizingPath()) of NSURL)
repeat with i from 0 to the pageCount() - 1
set end of pdf_pages to the |string|() ¬
of the pageAtIndex_(i) as text
end repeat
end tell
return the pdf_pages
end pdfText
get pdfText from "/Users/CK/Downloads/Under_15_Gold.pdf"
It grabs the text verbatim, going from left-to-right, and top-to-bottom through each text object.
The result is a list, each item containing the text from an individual page in order. I’ll leave the parsing to you to isolate the bits you need versus the stuff you don’t,
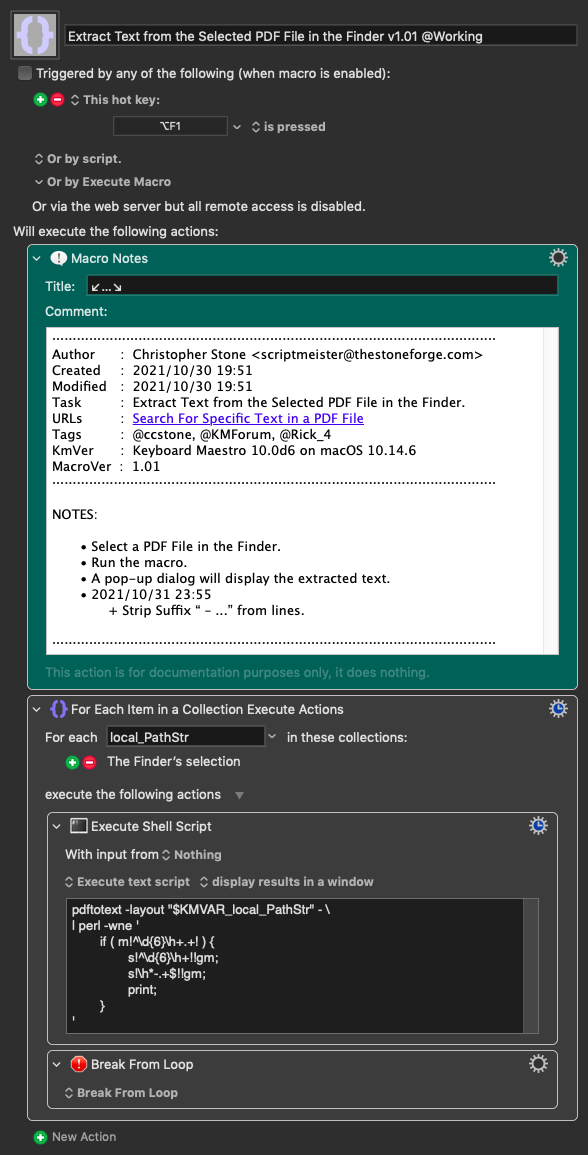
Okay, extracting text from the PDF works as expected.
Unfortunately @CJK's AppleScriptObjC method produces garbled text that's really hard to work with, but fortunately there's a tool available with a switch that maintains the original document layout as much as possible.
If you don't own it already it will be fully featured during the 30 day demo period and then revert the the freeware “lite” version. The lite version is still very powerful and scriptable.
I use it for programming and for viewing plain text documents.
I've tried your Macro many times and works perfectly, thank you very much.
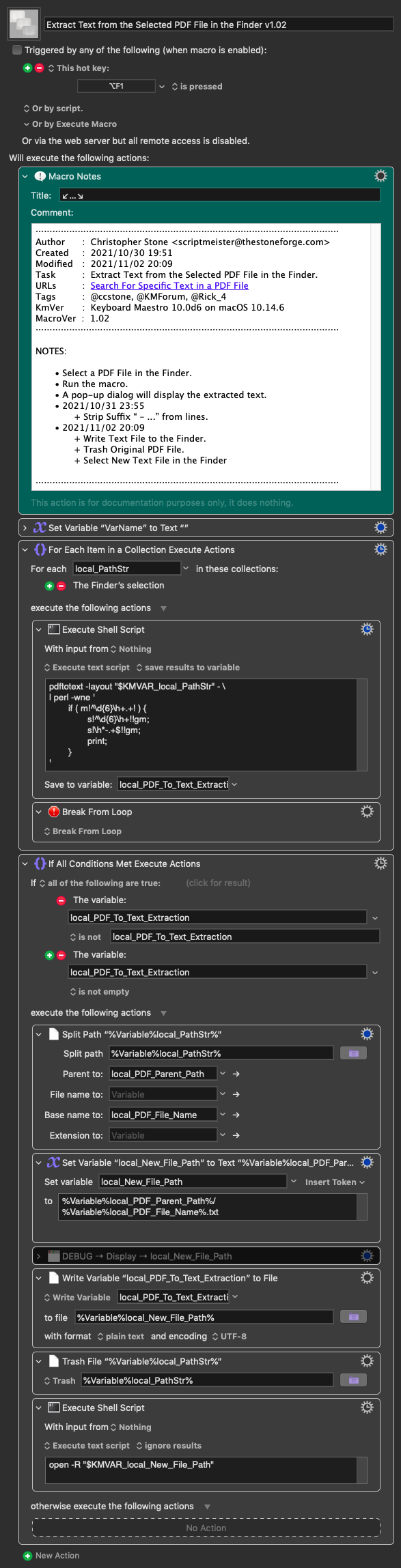
But now, I'm trying to script also the line "Girone: Girone something" in order to create a new txt file with name "name of the current document + _Gironesomething".
Take as an example the PDF file I've posted. From this, I'm using the Macro you posted (Extract Text from the Selected PDF File in the Finder v1.02), to execute the shell Script.
So from this kind of PDF file i would like to create a new txt file like this:
So you want to break up the PDF into individual text files containing each group's information and named for the original document plus the group name – yes?
Just like with the previous task – you need to post the actual PDF files for testing.