It's here at last, the new and improved Textcavator for full text searches of files on your computer.
Because it's like Googling your hard drive, we created a simplified interface for it:
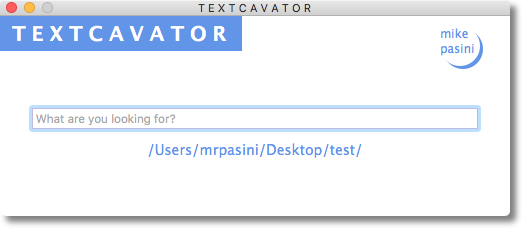
The full interface with new options to refine a search is still available by holding down the Shift key with the trigger (F9 in this distribution).
And the report form has been redesigned to make it easy to see what options were used and to scroll within the report window.
The original Textcavator is still available but this one is different enough that I'm starting a separate thread.
Textcavator 2020.zip (1.6 MB)
(NB: Slight revision to Perl code to remove redundant filename in report used for debugging. Added pdftotext installation instructions.)
Original Textcavator page. (@ccstone -- Keyboard Maestro Moderator)
Newest Version Textcavator 2021 (@mrpasini)
5 Likes
Question: from where exactly do I download the pdftotext handler? Thanks!
Hmmm, I didn't mention that, did I? I installed the free macOS binary from http://www.xpdfreader.com/download.html in /usr/local/bin.
1 Like
Is it the "Mac 64-bit" item?

Yes. You’ll find a directory in the unzipped folder with pdftotext in it.
1 Like
Thanks, I found it. I double-clicked on "pdftotext" and watched Terminal open and seem to install the handler. However, when I run Textcavator with the pdftotext box checked, on a folder full of what should be searchable PDFs, like this, I get no hits. I understand that for some PDFs, text can't be rendered due to multiple rounds of OCR, for example; but that's not the case with these PDFs, which are legal cases downloaded from legal databases and which are fully searchable if opened in Preview. Is there something I need to change in the macro for it to detect and use the handler, or something I need to do to initialize the handler in Terminal?
Doesn't sound like you copied pdftotext to /usr/local/bin (that's where the Perl script looks for it:
system(`/usr/local/bin/pdftotext "$filename"`);
If you put your pdftotext on the Desktop, you can copy it with:
cp ~/Desktop/pdftotext /usr/local/bin sudo
which will prompt for your admin password before copying.
The only PDFs which won't convert are ones without text (with a picture of text, instead, where the text is all bitmaps). You can OCR those first to get a text version.
1 Like
Thank you for the instructions and your patience. I think I've got it now!
Thanks for pointing out the omission from the manual. I'll add that shortly. [Done]
Usage Tip
You can speed Textcavator up by processing a directory of PDFs into text files with pdftotext and pointing Textcavator to the text files. This also works well for proprietary files (like InDesign) that have their own export to text option.
If you have mixed file types in a directory, though, adding a text conversion will only cause Textcavator to read the original and the conversion both.
And then, of course, you can add that directory to A Few Favorites Macro to zip over there and run Textcavator on it.