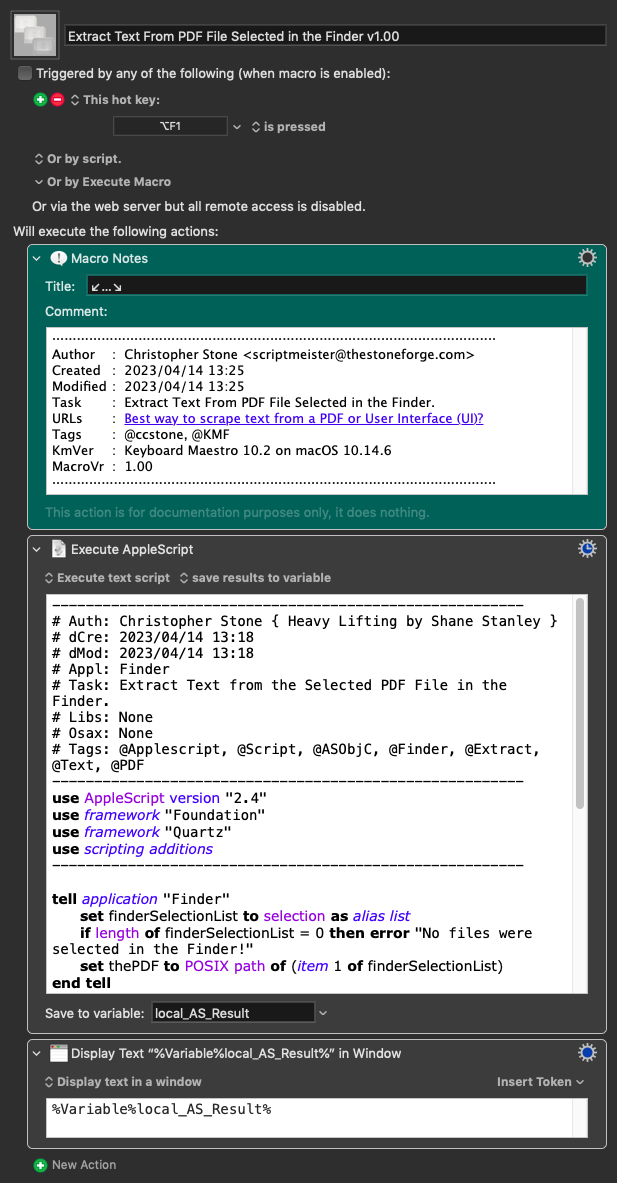
So for a long time I have needed to extract information from various standard government forms and User Interface elements, and I have been using really dumb brute force mechanisms. I was wondering what others do to extract such info?
There seems to be maybe 4 mechanisms (Brute force clicks, image search, some sophisticated UI inquiry, perhaps an OCR technique) that I’m aware of, but each has issues and I’m wondering what others use/do to get/pull/scrape out information they need to operate on from a document or UI element.
Brute force
For example, have KM make a PDF window a set size in Preview.app and then just double click some exact X/Y location in the document and copy the selected text. This used to work well enough in most cases in the past. I would also do this to automate parts of interacting with the UI, just make KM click at an XY location to click a button. It mostly works. Of course a big problem with brute force is that Apple changes the UI font/spacing and the macro clicks will break. Or the form I’m working with will be scanned and the positioning of a form element will be off just enough that a click may be misaligned and get the wrong data. Also, now that Apple OCRs text you click on in a PDF it copies the invisible already OCRd text from the PDF and the apple OCR from the click on the bitmap and you end up copying double values.
Image search
I’ve tried this and it works ok some\times but is generally unreliable and weirdly variable. For example, I may grab a screen image of an “OK” or “Save” button in a UI to click on, and it will rightly click on it 9 out of 10 times but seems to fail. A lot of times I think the failure was if the screen went into dark mode I guess the image match fails regardless of how much slack you give on the tolerance slider. Fine I turn off dark mode, but it still fail, I suspect because some windows have subtle transparency and depending on where the window will pop up with some variable background image, I guess the image search can’t see.
Worse still, if I try to look for some text field in a PDF document like “Mailing Date” to then click the text to the right of it and scrape out the mailing date, it fails 50% of the time and doesn’t see “Mailing date” I’m guessing because of subtle differences in how that text was rostered from form to form. But the visual search also fails hard for text in the user interface, like the soft grey text in a mail.app compose window for “Subject” or “ CC:” despite such rendering supposedly being identical in every window (perhaps again because those windows have soft transparency so the bitmap it finds on becomes just too different).
Sophisticated UI inquiry
I believe with apple script there are some cool ways you can query for different values of a UI. So there may be someway to say what is the text field in this window, or the text value of this button in a panel. KM has at least some ways of getting at some UI elements, like the name of a window. But I’m not familiar is there some kind of command that says “find a UI button with text containing ‘save’ and engage it” or “find a right click menu item that contains text “export and engage it” or something like that? My guess is it’s not possible without some AppleScript hacking but perhaps I’m missing something simple.
OCR technique
All I really want to do with scraping some info from a PDF is look for a field prompt and copy out some characters to the right or below that field. So for example I might have “Re:”-line that will have some subject to the right of that line, and a “Mail Date:” that may have a mailing date just to the right of that label, and a “Return Address:” just below that label. I know that KM can OCR a document but I didn’t see any selection scraping tools from that OCR’ing. For example, is there something like “OCR for ‘Mail Date: and select next 10 characters’ type of command?
TLDR: Anyway, for now I use a mishmash of brute force and image searching but I get the feeling I’m missing much better ways to target those PDFs and UI elements and copy out those values and or engage the UI elements … and I’m hoping others here have some great silver bullet reliable ways to extract/scrape such values! Thanks so much for any pointers or a sanity check that in fact that’s about all that can be done with KM for scraping out data from the UI and PDFs.