Overall objective
This series is designed to help those looking to use sqlite3 databases with their Keyboard Maestro macros. It assumes minimal to no knowledge of sqlite3, and I'll do my best to clearly explain things as I go.
If you have questions, please ask and I'll do my best to clarify.
By the end of the series, you'll hopefully have a functional Keyboard Maestro macro that creates a database, and then interacts with that database to read data, change data, add data, etc. With the knowledge gained during the creation of that macro, you should then be able to add database support to your own macros when you see the need.
That's the objective, anyway :).
Part One: You're reading it
Part Two
Part Three
Part Four
Overview of Part One
This first part is focused on the database side of things: Why you might want one, some very general design guidelines, and then the introduction of the tutorial project (a sales tracking database) and creating a database in a third-party app to test things out and get comfortable with sqlite3. But this isn't just busywork, as this is also actually the first step in getting a database set up in Keyboard Maestro.
By the end of this part, you should have a basic grasp of simple database design, tables and key fields, creation of a database using a third party app, and using some SQL commands to manipulate the data in the database.
Do you need a database?
Before you do any macro writing in Keyboard Maestro (KM), you first need to decide if you actually need a database. I look at a couple of things when deciding whether it's worth the effort to set up a database:
-
Does the data need to exist permanently, and is there a lot of it? If yes, then a database is probably a good option. Keeping lots of large global variables around in KM isn't necessarily good, as they consume memory and it's incredibly easy to accidentally delete a variable.
-
Do I have a large number of fields that I need to process? In my Quick Web Search macro, I was tracking shortcut keys, URLs, activation state, type of shortcut, and descriptions. In an early version of the macro, I kept all this data in a large multi-row variable, using delimiters to separate the pieces. I'd then use regular expressions to extract the bits I needed to work with, but this soon got to be incredibly complicated. A database simplifies things by letting me write very simple queries to extract just the data I need.
There are probably other criteria you should consider, but for me, those are the big two.
Now, put away Keyboard Maestro, because you're not going to need it for the first part of the tutorial. This first part is all about sqlite3 databases. It's very important as a baseline for what the other parts will cover, as you'll need some level of comfort with what they are and how they work.
Database design principles
Assuming you've decided you want to use a database, you need to figure out how you want it structured. I am not going to try to go into a detailed primer on databases, mainly because that's not my area of expertise and there are tens of thousands of words written on the subject already.
At an overview level, a database is just a collection of tables of data that can be related to each other in some manner. A table is nothing more than a list of attributes (Mac Name, Year, Base RAM) and values (Studio, 2022, 8GB). Think of the attributes as the columns in a spreadsheet, and the each set of values is a separate row.
Generally speaking, a database will consist of a number of small (as measured by attribute count) tables, and each of those should have a unique key field. (In the Mac-related examples I just used, such an attribute might be Apple's model number, which is unique per Mac model.) You can then use a variety of SQL commands to combine the tables, using those key fields, to get the results you want.
Whether you want to do that, or just build a monolithic table without any keys connecting to other tables (which is how MacroBackerUpper's Settings database is built) is really up to you and how you intend to use the database.
For example, in MacroBackerUpper (MBU), I use the Macros database (which is separate from the Settings database) simply as a means of accessing data: I'm not updating any of the records, other than adding flags based on their determined status. The raw data that I get out of KM looks like this:
Macros: Group ID, Macro ID, Macro Name, Macro Status
Groups: Group ID, Group Name, Group Status
Traditional database design says that I should have two tables, each with the above fields in them, and with the ID fields being keys. If I set things up that way, and then wanted to retrieve some data including a macro's owning group name, I'd get it with a SQL statement:
SELECT
ms.Macro_Name, ms.Macro_ID, ms.Macro_Status, gs.Group_Name
FROM
Macros ms
JOIN
Groups gs
ON
ms.Group_ID = gs.Group_ID
WHERE
ms.Macro_ID = '1234567';
This would retrieve the name, ID, status, and matching group name (from the Groups table) for the macro with ID number 1234567.
——————
A quick aside on those two-letter-words in the above SQL, i.e. ms.Macro_ID and gs.Group_ID. The short words (they don't have to be two letters) are aliases for the longer table names, and they're assigned when you first reference the table (FROM Macros ms). So instead of typing Macros.Macro_ID, you can just type ms.Macro_ID. They're very useful in queries that involve multiple tables.
———————
But I knew I was going to want the associated Group Name for a given macro almost every time, and I didn't want to have to deal with two tables every time I wanted the group name. So instead, I designed my two tables like this:
Macros: Group ID, Macro ID, Macro Name, Macro Status, Group Name (plus other fields I use)
Groups: Group ID, Group Name, Group Status (plus other fields I use)
I pre-merge the group name into the Macros database when I build it. (A future installment will cover how those tables are pre-merged.) By doing so, I can always grab the group name whenever I'm working with a given macro without referencing the Groups table:
SELECT
Macro_Name, Macro_ID, Macro_Status, Group_Name
FROM
Macros
WHERE
Macro_ID = '1234567';
That's a much simpler construct, and probably a millisecond or two quicker, as the database doesn't have to do a JOIN. But if this were a database where I was adding and removing and renaming groups all the time, this would be a terrible design: I'd have to re-merge the data after every change.
But I'm not doing that; I actually delete half the database after every run, and rebuild it with the next run. As such, pre-merging saves me a lot of work when pulling data from the database.
So the final design is really dependent on your needs.
Note that if you're sharing your macro, you want to do your best to cover any eventuality in the initial design. If you need to update the database with a new table and/or fields, the next release of your macro will have to include code that checks for the existence of the new elements in the database, and adds them if required—otherwise, steps in the macro that rely on those new elements will fail.
Learning sqlite3
There are tons of resources out there for learning SQL (the language you use to talk to the database), but you make sure you find one that focuses on sqlite3, as there are a few key differences in the way it operates. I did a quick search, and it looks like SQLite Tutorial is pretty good. It's written in an easy-to-follow manner and progresses from really simple stuff to quite advanced stuff. But I'm sure there are dozens of others.
The important thing to know is that you do not need to be an expert at sqlite3 commands to use a database with your macro. My knowledge going in was middling, as I'd done some work with SQL, but that was literally decades ago. But because most databases you'll build for use with your macros are simple, you're probably only going to need the basic commands for adding, updating, extracting, deleting, etc., and those aren't hard to pick up.
And, as it turns out, ChatGPT is really good at sqlite3—just make sure you clearly tell it you're using sqlite3 so that it gives you the correct format of the various SQL commands (there are differences amongst the SQL databases out there). As you'll see in a future installment, ChatGPT helped me a lot with some of the more complex SQL commands in MBU. (And later on in this first part, you'll see how it works.)
The tutorial project
For this project, we'll be building a simple sales tracking database. It will be used to record sales by salesperson, region, and product, and then various data will be extracted from the database. It will also include a settings table, for storing user preferences. The first step in building this database is to design its structure (tables and key fields).
If I need to layout a simple one or two table database, I'll just jot some thoughts down in Notes or a text editor, and that's usually enough to get me going. But for more complicated things, I need to lay out the tables, fields in those tables, and relationship between the tables to help me understand the data flow, and to get a good picture of the overall structure.
There are dedicated tools for this, but I find Keynote works quite well, given its ability to insert tables with rows and columns and to add graphics such as lines and arrows.
Considering the sales tracking database, I designed it to use these tables:
-
Employees: The people employed to sell our products.
-
Regions: The areas in which our products are sold.
-
Products: The products we sell.
-
Sales: The actual sales of our product, with one sale per row.
-
Settings: The user preferences for our system.
And here's the design I came up with in Keynote, reflecting that structure…
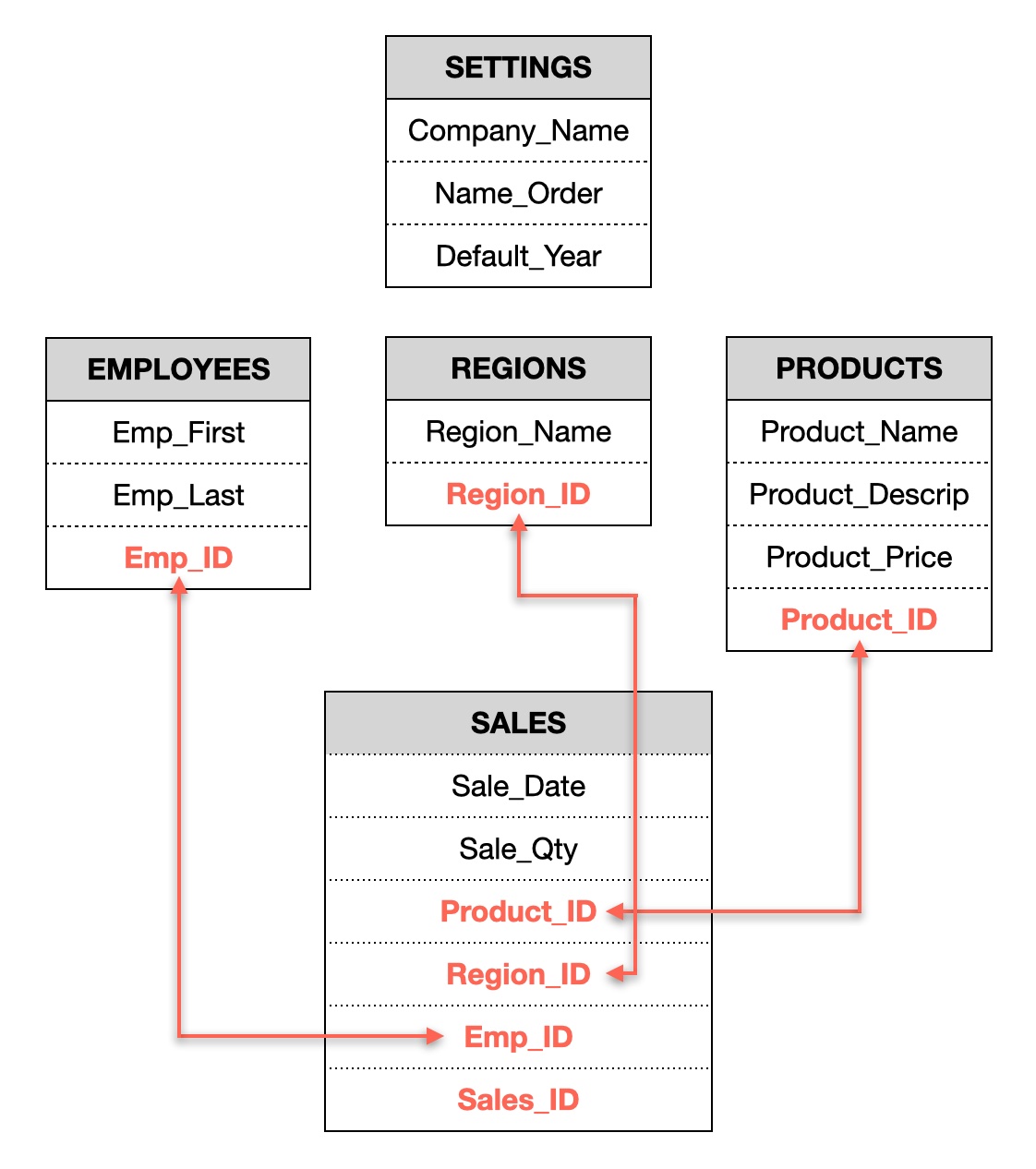
This is greatly simplified from what a "real" sales tracking database would need (Employees would need hire date, wage info, etc.) … but then again, you shouldn't be trying to write a full-blown sales tracking database app in Keyboard Maestro. It is, however, more than detailed enough to demonstrate how to use sqlite3 in Keyboard Maestro.
In the Employees table, we have each employee's name and ID number. In Regions, we have a region name and ID number. Products is the most complex table, as it's got a product name, description, price and product ID. The Sales table has only three pieces of new information: The date of sale, the quantity sold, and the sale ID. Unlike the IDs in the other tables, the sales ID will be a number generated by the database itself.
Three other elements of that table—the employee's ID, the region's ID, and the product's ID—are just links to those respective tables. In our system, when we enter a sale, we'll enter the date and quantity sold, then select the salesperson, region, and product from lists extracted from the database.
By storing the various table IDs with each sale, it will allow extraction of related data from the other tables. For example, a sales report by employee showing their full names can be created with these SQL commands:
SELECT
emp.Emp_Last || ', ' || emp.Emp_First AS Employee_Name,
SUM(sls.Sale_Qty * prd.Product_Price) AS Total_Revenue
FROM
Sales sls
JOIN
Employees emp ON sls.Emp_ID = emp.Emp_ID
JOIN
Products prd ON sls.Product_ID = prd.Product_ID
GROUP BY
emp.Emp_First, emp.Emp_Last
ORDER BY
Total_Revenue DESC;
This is just one example (which you'll see in action a bit further on), but it shows how the key fields allow merging data from multiple tables. (For now, don't worry about the intricacies of that SQL, it's just an example of data extraction from related tables.)
Finally, the Settings table tracks a few things that a user might wish to set for their use of the sales tracking database. Note that table names and field names are completely up to you. My personal preference is to avoid spaces in names, so I use underscores where I might have used a space, or stick to single-word names.
Creating a database
With the database design done, the next step is to play with it a bit and make sure it works as you'd expect—and no, that's not done in Keyboard Maestro. At least not yet.
Instead, there are any number of third-party tools that work with sqlite3 databases. After trying most of them, the one I wound up sticking with is DB Browser for SQLite. You are welcome to use whatever tool works best for you, but all the examples in this tutorial will be using DB Browser for SQLite. It's not the prettiest app, but it's free to use (donations encouraged) and it works very well.
In DB Browser, click the New Database button at top left, and choose a name and location for your database. (Note: This isn't just an exercise in learning DB Browser; when done, the app will have written the SQL statements we'll eventually use to create the database in our tutorial macro.)
This database will not be connected to the database that will eventually be built within KM, so it doesn't matter where you save it nor what you name it—it's just for playing around with. Once you pick a name and location, a new dialog appears, asking you to provide a table name and to create some fields on that table:
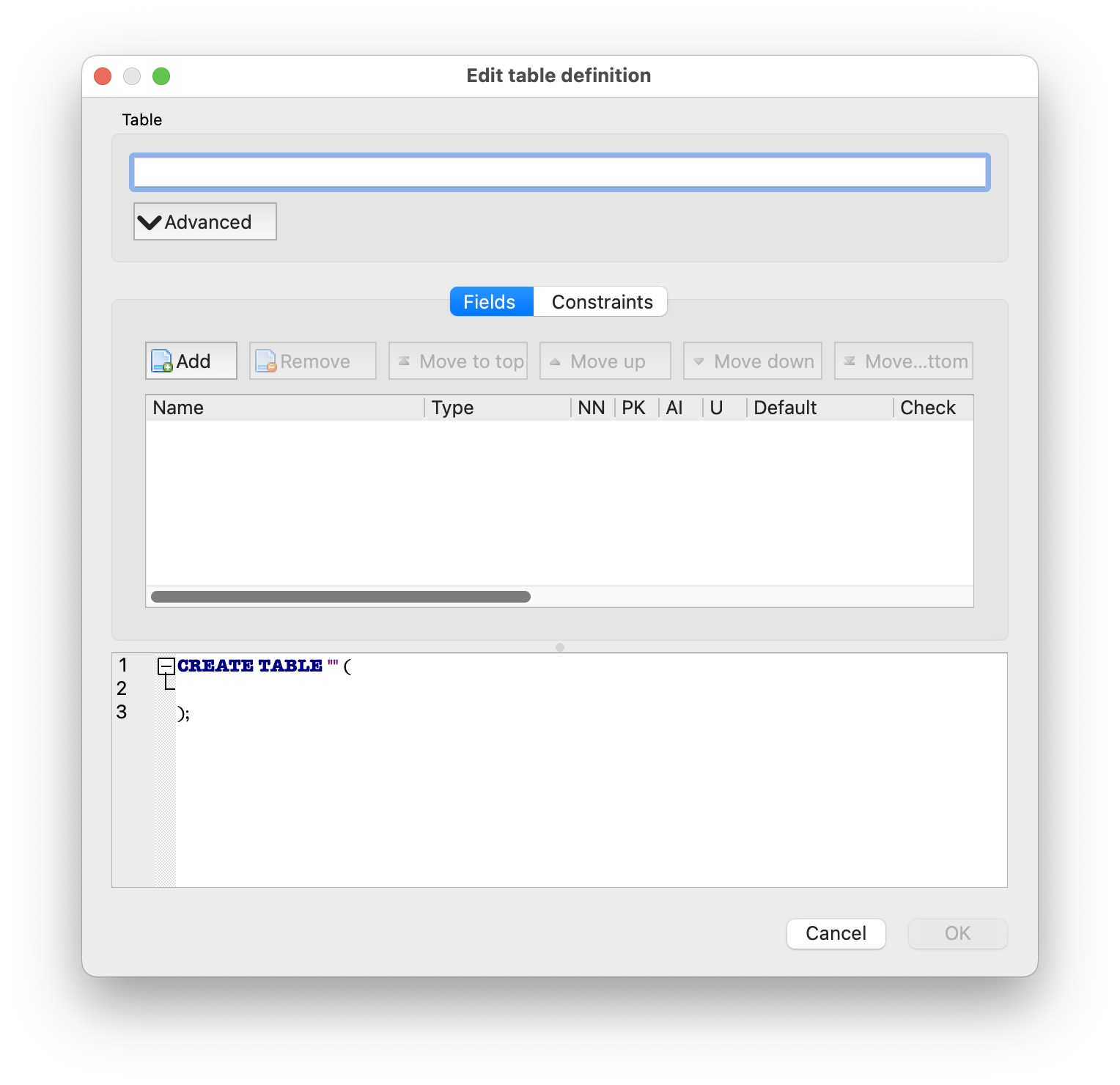
We'll create the Employees table first, so type Employees in the top box, then click the Add button in the Fields section. For the first field, enter the Name as Emp_First and set the Type to Text. Repeat with the other two fields until the dialog looks like this:
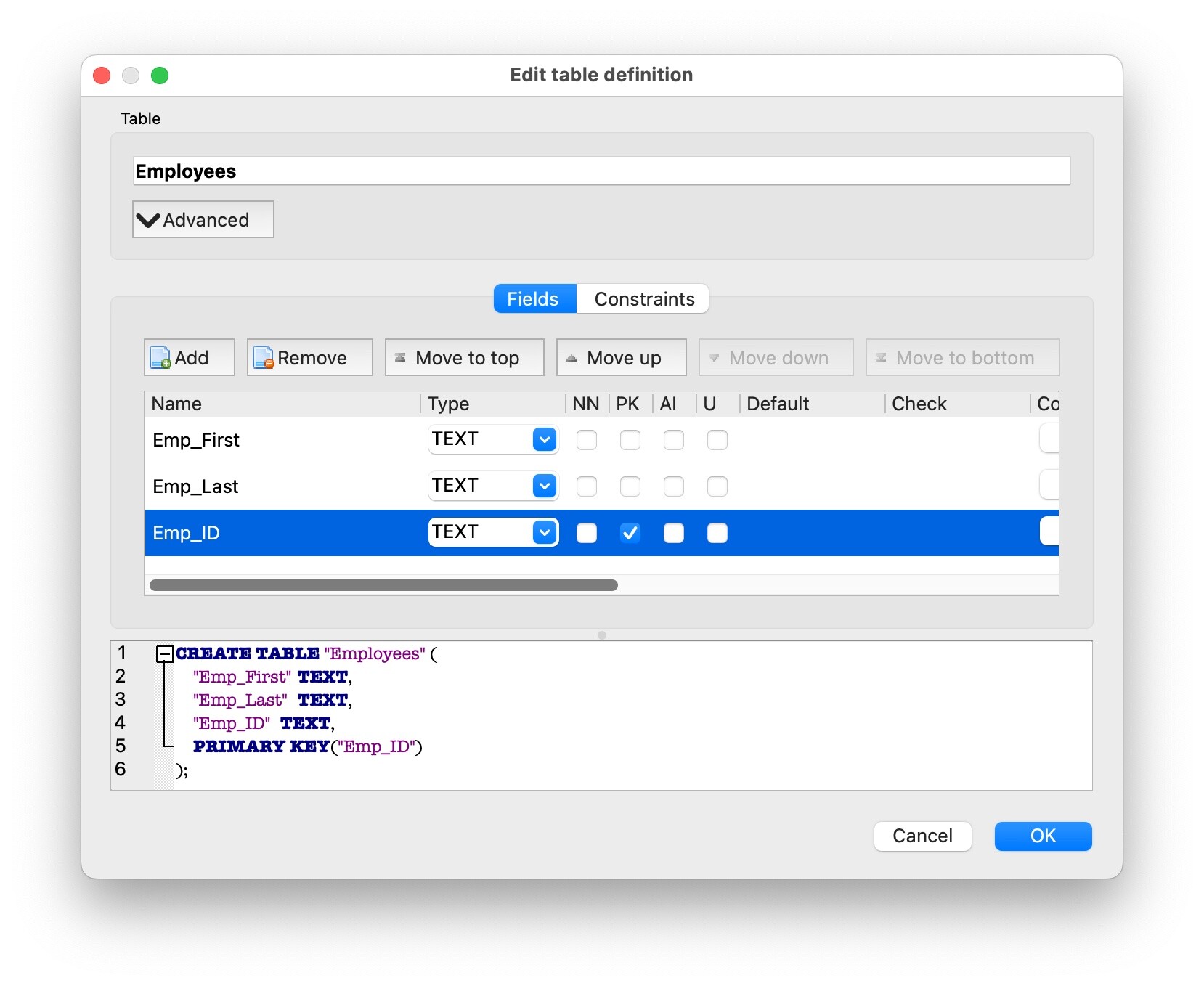
Notice that the last field, Emp_ID, has a check in the "PK" column. What is "PK"? If you hover over each of the column headings, a pop-up will reveal what they do—"PK" means Primary Key, and each table can have only one primary key (though that key can consist of multiple columns).
A primary key insures that each record has a unique identifier in the table, and also allows linking to other tables via that key. Here's a detailed writeup on primary keys, as well as unique keys, which are related but different.
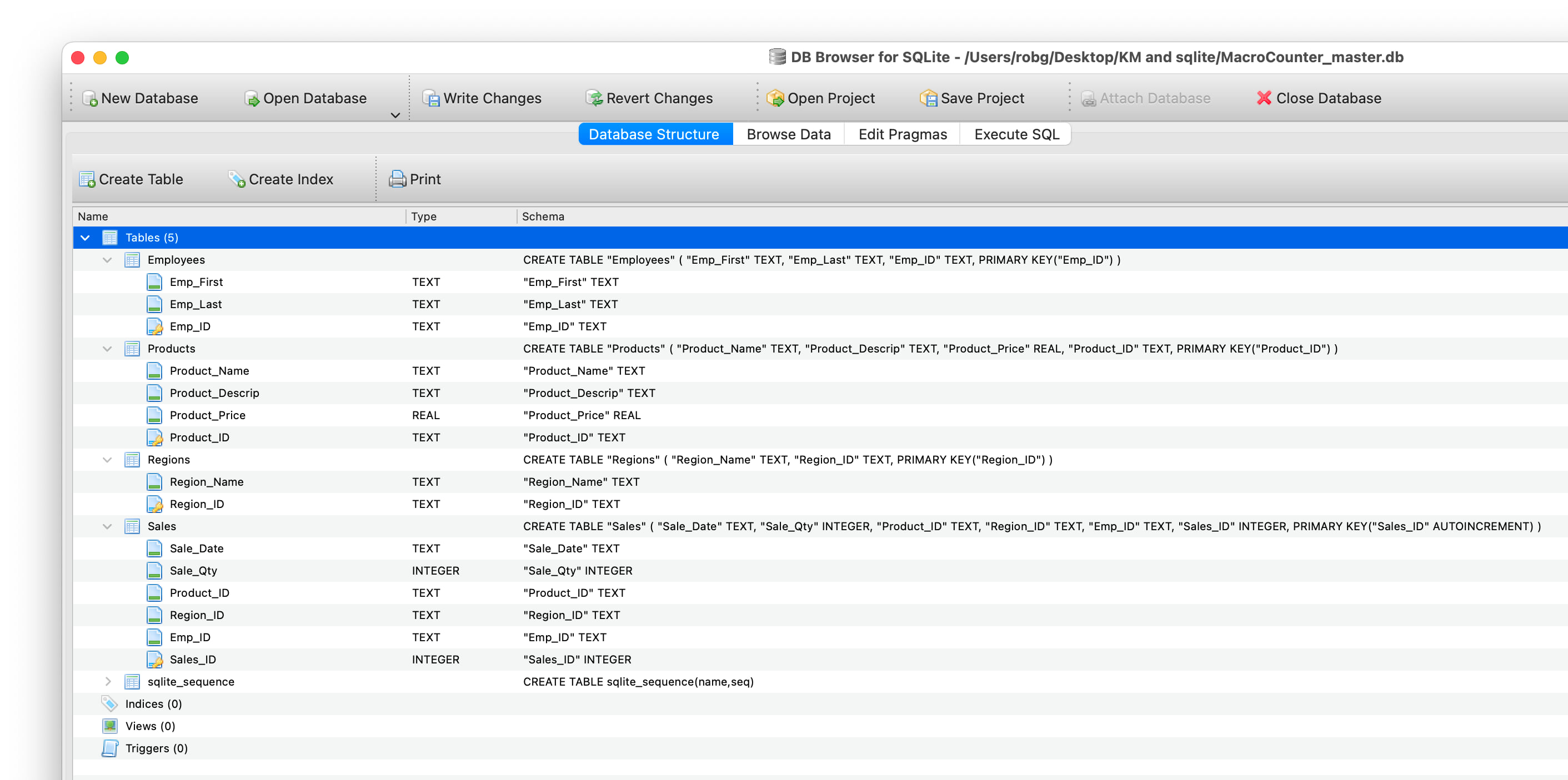
Click OK, and the dialog will close and the table will be added to your database—click on Database Structure and expand the Tables section to see it.
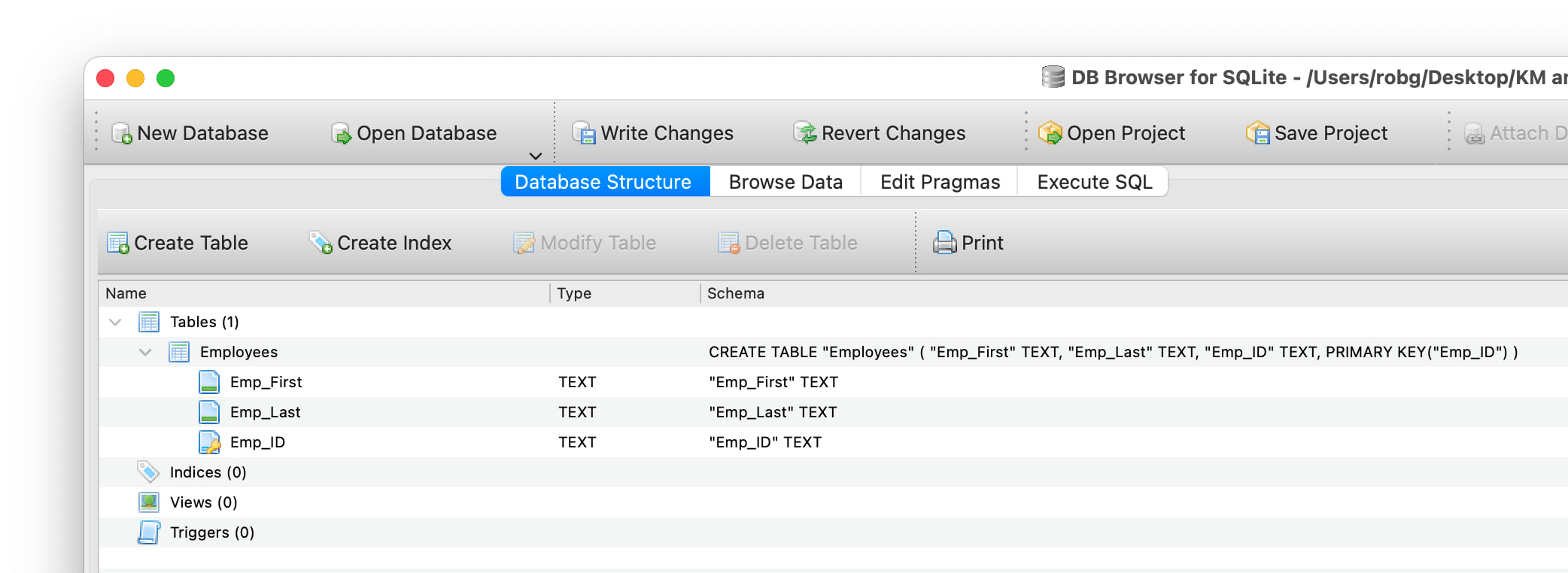
The other tables need to be created, so click the Create Table button, and add the Regions table, set up the fields, click OK, then repeat for each of the other tables in the database (don't worry about creating the Settings table yet; we'll do that in a future installment).
Here are the settings you'll need for each table's fields:
-
Regions: Region_Name is Text, Region_ID is Text and Primary Key is checked.
-
Products: Product_Name and Product_Descrip are Text. Product_Price is Real, and Product_ID is Text and Primary Key is checked.
-
Sales: Sale_Date is Text, Sale_Qty is Integer, and Product_ID, Region_ID, and Emp_ID are all text—but not Primary Key! Sales_ID is Auto Incrementing and Primary Key.
When done, it should look like this:
Alternatively, if you'd like to cheat (hehe), cancel out of the new table dialog, switch to the Execute SQL tab, and paste this in:
The cheater's SQL
CREATE TABLE IF NOT EXISTS "Employees" (
"Emp_First" TEXT,
"Emp_Last" TEXT,
"Emp_ID" TEXT,
PRIMARY KEY("Emp_ID")
);
CREATE TABLE IF NOT EXISTS "Regions" (
"Region_Name" TEXT,
"Region_ID" TEXT,
PRIMARY KEY("Region_ID")
);
CREATE TABLE IF NOT EXISTS "Products" (
"Product_Name" TEXT,
"Product_Descrip" TEXT,
"Product_Price" REAL,
"Product_ID" TEXT,
PRIMARY KEY("Product_ID")
);
CREATE TABLE IF NOT EXISTS "Sales" (
"Sale_Date" TEXT,
"Sale_Qty" INTEGER,
"Product_ID" TEXT,
"Region_ID" TEXT,
"Emp_ID" TEXT,
"Sales_ID" INTEGER,
PRIMARY KEY("Sales_ID" AUTOINCREMENT)
);
Click the Play button, and your database will be created. As a bit of a future preview, that's the code we'll eventually use in a KM macro to create the database.
Testing your database
Now that the database exists, it's time to add some data and see how it works. Thanks to ChatGPT, the data population bit is greatly simplified—normally I'd have to make up all this stuff on my own, but I just asked it to generate some sample data. Switch to the Execute SQL tab, and then paste this in:
Employees
INSERT INTO Employees (Emp_First, Emp_Last, Emp_ID)
VALUES
('John', 'Doe', 'E001'),
('Jane', 'Smith', 'E002'),
('Michael', 'Johnson', 'E003'),
('Emily', 'Williams', 'E004'),
('Christopher', 'Jones', 'E005'),
('Sarah', 'Taylor', 'E006'),
('David', 'Brown', 'E007'),
('Olivia', 'Davis', 'E008'),
('Daniel', 'Miller', 'E009'),
('Sophia', 'Moore', 'E010');
Click the Play button in the toolbar, and congrats: You now have 10 employees! Repeat with this data for the remaining tables—expand each hidden section below, copy the SQL, paste into DB Browser (replacing the SQL that may be there), then click Play.
Regions
INSERT INTO Regions (Region_Name, Region_ID)
VALUES
('West', 'R001'),
('Midwest', 'R002'),
('Southwest', 'R003'),
('South', 'R004'),
('East', 'R005'),
('Northeast', 'R006');
Products
INSERT INTO Products (Product_Name, Product_Descrip, Product_Price, Product_ID)
VALUES
('Sprocket', 'High-quality bicycle sprocket for smooth and efficient chain movement. Durable construction for long-lasting performance.', 19.99, 'P001'),
('Pedals', 'Lightweight and sturdy bicycle pedals with grip-enhancing surface. Perfect for both casual and professional cyclists.', 29.99, 'P002'),
('Seat', 'Ergonomic bicycle seat designed for maximum comfort during long rides. Adjustable and suitable for various bike types.', 39.99, 'P003'),
('Handlebar Grips', 'Comfortable handlebar grips with non-slip design. Enhance your grip and control during rides. Easy to install and durable.', 12.99, 'P004'),
('Chain', 'Durable bicycle chain for smooth and reliable gear shifting. Suitable for various bike models. Easy to maintain and install.', 24.99, 'P005'),
('Brake Pads', 'High-performance brake pads for efficient and responsive braking. Suitable for different weather conditions. Easy to replace and install.', 17.99, 'P006'),
('Tire Tube', 'Quality bicycle tire tube for a smooth and puncture-resistant ride. Compatible with various tire sizes. Easy to install and inflate.', 14.99, 'P007'),
('Headlight', 'Powerful LED headlight for enhanced visibility during night rides. Easy to mount and suitable for various bike models. Long battery life.', 32.99, 'P008'),
('Taillight', 'Compact and bright taillight for increased safety during night rides. Multiple lighting modes and easy to attach to the bike frame.', 14.99, 'P009'),
('Fenders', 'Stylish and durable bicycle fenders to protect against mud and water splashes. Easy to install and suitable for various bike types.', 21.99, 'P010'),
('Bike Lock', 'Secure your bike with a robust and reliable bike lock. Durable construction and easy to carry. Enhance your bike''s security.', 27.99, 'P011'),
('Water Bottle Holder', 'Convenient water bottle holder for easy access during rides. Lightweight and adjustable to fit different bottle sizes.', 9.99, 'P012'),
('Bike Pump', 'Compact and efficient bike pump for quick and easy tire inflation. Suitable for Presta and Schrader valves. Essential for every cyclist.', 19.99, 'P013'),
('Multi-Tool Kit', 'Versatile and compact multi-tool kit for on-the-go bike repairs. Includes various tools for common maintenance tasks. Durable and portable.', 16.99, 'P014'),
('Bike Rack', 'Sturdy and adjustable bike rack for secure storage. Suitable for garage or outdoor use. Protect your bike and save space with this rack.', 34.99, 'P015');
Sales
INSERT INTO Sales (Sale_Date, Sale_Qty, Product_ID, Region_ID, Emp_ID)
VALUES
('2023-01-01', 5, 'P001', 'R001', 'E001'),
('2023-01-02', 8, 'P002', 'R002', 'E002'),
('2023-01-03', 10, 'P003', 'R003', 'E003'),
('2023-01-04', 15, 'P004', 'R004', 'E004'),
('2023-01-05', 7, 'P005', 'R005', 'E005'),
('2023-01-06', 12, 'P006', 'R006', 'E006'),
('2023-01-07', 3, 'P007', 'R001', 'E007'),
('2023-01-08', 6, 'P008', 'R002', 'E008'),
('2023-01-09', 9, 'P009', 'R003', 'E009'),
('2023-01-10', 4, 'P010', 'R004', 'E010'),
('2023-01-11', 5, 'P001', 'R002', 'E002'),
('2023-01-12', 8, 'P002', 'R003', 'E003'),
('2023-01-13', 10, 'P003', 'R004', 'E004'),
('2023-01-14', 15, 'P004', 'R005', 'E005'),
('2023-01-15', 7, 'P005', 'R006', 'E006'),
('2023-01-16', 12, 'P006', 'R001', 'E007'),
('2023-01-17', 3, 'P007', 'R002', 'E008'),
('2023-01-18', 6, 'P008', 'R003', 'E009'),
('2023-01-19', 9, 'P009', 'R004', 'E010'),
('2023-01-20', 4, 'P010', 'R005', 'E001'),
('2023-04-11', 3, 'P011', 'R001', 'E001'),
('2023-04-12', 6, 'P012', 'R002', 'E002'),
('2023-04-13', 8, 'P013', 'R003', 'E003'),
('2023-04-14', 12, 'P014', 'R004', 'E004'),
('2023-04-15', 5, 'P015', 'R005', 'E005'),
('2023-04-16', 10, 'P001', 'R006', 'E006'),
('2023-04-17', 7, 'P002', 'R001', 'E007'),
('2023-04-18', 4, 'P003', 'R002', 'E008'),
('2023-04-19', 9, 'P004', 'R003', 'E009'),
('2023-04-20', 2, 'P005', 'R004', 'E010'),
('2023-04-21', 8, 'P006', 'R005', 'E001'),
('2023-04-22', 5, 'P007', 'R006', 'E002'),
('2023-04-23', 3, 'P008', 'R001', 'E003'),
('2023-04-24', 11, 'P009', 'R002', 'E004'),
('2023-04-25', 6, 'P010', 'R003', 'E005'),
('2023-04-26', 14, 'P011', 'R004', 'E006'),
('2023-04-27', 7, 'P012', 'R005', 'E007'),
('2023-04-28', 9, 'P013', 'R006', 'E008'),
('2023-04-29', 4, 'P014', 'R001', 'E009'),
('2023-04-30', 10, 'P015', 'R002', 'E010');
If you select the Browse Data tab now, you'll find you have data in all your tables. As an example of what you can now do, consider the SQL I showed earlier to create a sales report:
The sales report SQL
SELECT
emp.Emp_Last || ', ' || emp.Emp_First AS Employee_Name,
SUM(sls.Sale_Qty * prd.Product_Price) AS Total_Revenue
FROM
Sales sls
JOIN
Employees emp ON sls.Emp_ID = emp.Emp_ID
JOIN
Products prd ON sls.Product_ID = prd.Product_ID
GROUP BY
emp.Emp_First, emp.Emp_Last
ORDER BY
Total_Revenue DESC;
Paste and run that in the Execute SQL tab, and you should see results like this:
EMPLOYEE | SALES
-------------------|---------
Taylor, Sarah | 982.57
Williams, Emily | 963.52
Johnson, Michael | 898.71
Jones, Christopher | 676.67
Moore, Sophia | 622.75
Davis, Olivia | 582.78
Brown, David | 540.71
Miller, Daniel | 517.72
Smith, Jane | 474.76
Doe, John | 415.80
That's an amazing amount of data analysis hiding in about a dozen lines of SQL.
With the data in the database, you can do a ton of other stuff, but I'll save that for the future installments. For now, play around with this, and practice doing some basic (or not so basic) SQL queries, such as:
How many Multi-Took Kits (ID #P014) did Emily Williams (ID #E004) sell? (Answer = 12)
Don't peek! The SQL
SELECT
SUM(sls.Sale_Qty) AS Total_Quantity
FROM
Sales sls
JOIN
Employees emp ON sls.Emp_ID = emp.Emp_ID
JOIN
Products prd ON sls.Product_ID = prd.Product_ID
WHERE
sls.Product_ID = 'P014' AND emp.Emp_ID = 'E004';
Which region sold the most, in total? (Answer = South)
Don't peek! the SQL
SELECT
rgn.Region_Name, SUM(sls.Sale_Qty * prd.Product_Price) AS Total_Revenue
FROM
Sales sls
JOIN
Regions rgn ON sls.Region_ID = rgn.Region_ID
JOIN
Products prd ON sls.Product_ID = prd.Product_ID
GROUP BY
rgn.Region_Name
ORDER BY
Total_Revenue DESC;
Which individual day had the highest sales? (Answer = 2023-01-13)
Remember earlier when I said ChatGPT was really good at SQL? Here's an example of how you can put that skill to use. Here's how I would get ChatGPT to write the above SQL for me:
Using ChatGPT
Me:
I have this sqlite3 database:
CREATE TABLE IF NOT EXISTS "Employees" (
"Emp_First" TEXT,
"Emp_Last" TEXT,
"Emp_ID" TEXT,
PRIMARY KEY("Emp_ID")
);
CREATE TABLE IF NOT EXISTS "Regions" (
"Region_Name" TEXT,
"Region_ID" TEXT,
PRIMARY KEY("Region_ID")
);
CREATE TABLE IF NOT EXISTS "Products" (
"Product_Name" TEXT,
"Product_Descrip" TEXT,
"Product_Price" REAL,
"Product_ID" TEXT,
PRIMARY KEY("Product_ID")
);
CREATE TABLE IF NOT EXISTS "Sales" (
"Sale_Date" TEXT,
"Sale_Qty" INTEGER,
"Product_ID" TEXT,
"Region_ID" TEXT,
"Emp_ID" TEXT,
"Sales_ID" INTEGER,
PRIMARY KEY("Sales_ID" AUTOINCREMENT);
I need to find the single day with the highest total sales; what is the SQL to do that?
ChatGPT:
To find the day with the highest revenue, you can use the following SQL query. This query calculates the total revenue for each day and then identifies the day with the maximum revenue:
SELECT
Sale_Date,
SUM(Sale_Qty * Product_Price) AS Daily_Revenue
FROM
Sales sls
JOIN
Products prd ON sls.Product_ID = prd.Product_ID
GROUP BY
Sale_Date
ORDER BY
Daily_Revenue DESC
LIMIT 1;
In this query:
- We join the Sales and Products tables to get the necessary information about sales and products.
- We group the results by Sale_Date to calculate the total revenue for each day.
- We use the SUM(Sale_Qty * Product_Price) expression to calculate the daily revenue.
- The results are ordered in descending order by daily revenue using ORDER BY Daily_Revenue DESC.
- Finally, we use LIMIT 1 to get only the top result, i.e., the day with the highest revenue.
This query will return the Sale_Date and the corresponding total revenue for the day with the highest revenue. Adjust the column and table names as needed based on your actual database schema.
——————————————
Not only does ChatGPT write the SQL needed, but it explains how it works, helping you write your own SQL in the future. So don't be afraid to use ChatGPT for complex queries. Just remember to always test what it gives you in DB Browser before committing it to your database in Keyboard Maestro.
Conclusion
So much for Part One! Feel free to play around with the database; if you mess something up, just use the "cheater" SQL above to recreate the entire thing in the Execute SQL tab, then reimport the data for each table.
Part Two will explain some of the SQL statements you've seen here, talk about some cautions involving data formatting, then dive into how to get a database into Keyboard Maestro, including making sure it exists, recreating it if necessary, and writing a generic SQL handler. And if that's not too long, it will also demonstrate one way to add a sales record into the database…
I don't know when it'll be ready, but I'm working on it.