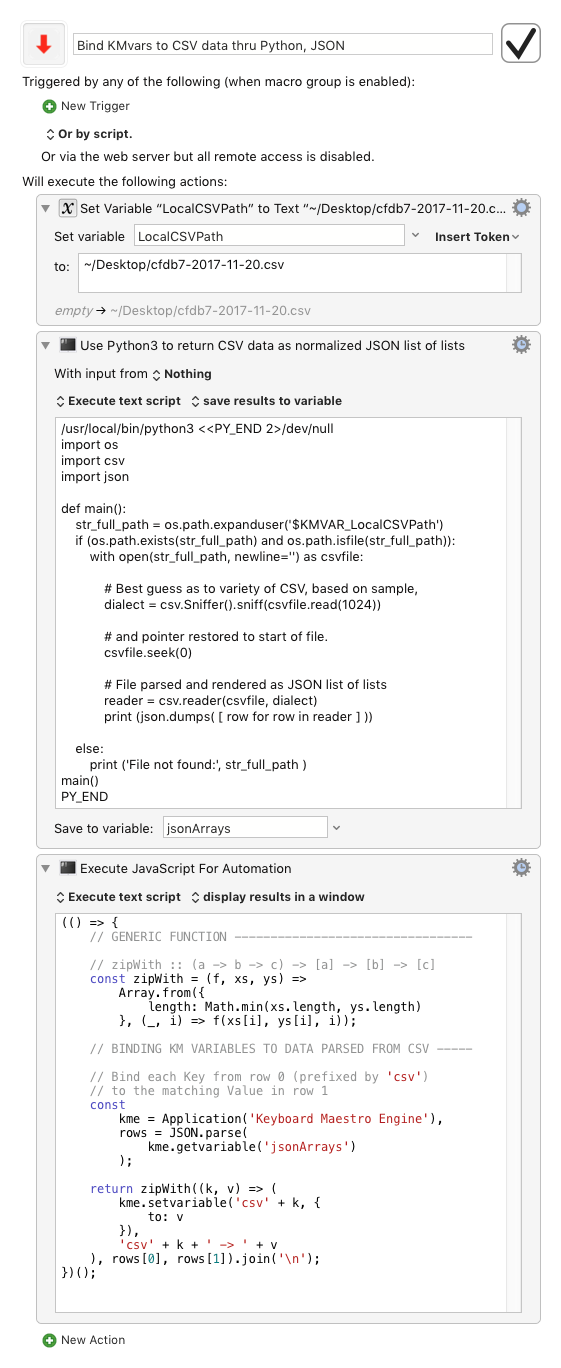
Various ways, I would probably write a short Execute JavaScript for Automation action in Sierra-onwards JavaScript (let me know if you are using an earlier macOS), and do something like the macro below:
(note that I have adjusted one line in the Python, to use print (json.dumps( [ row for row in reader ] ))
Bind KMvars to CSV data thru Python, JSON.kmmacros (20.3 KB)